Code
 Rocks
Rocks
text-generation-webui, également connu sous le nom de oobabooga, est une interface web basée sur Gradio qui permet d’interagir avec des modèles de langage larges (LLM), tels que ChatGPT, en local sur votre ordinateur. Cet outil se distingue par sa capacité à charger différents modèles de langage à travers une variété d’architectures, y compris avec support pour l’accélération graphique NVIDIA, offrant une flexibilité et des performances accrues pour le traitement du langage naturel.
Principales caractéristiques :
L’objectif de ce guide est de vous accompagner dans l’installation de text-generation-webui sur votre système et de charger un modèle de langage pour une utilisation immédiate. Cette fiche d’installation vous fournira les étapes nécessaires, de manière concise et informative, pour mettre en place cet outil versatile et commencer à explorer le potentiel des modèles de langage en local.
Avant de commencer l’installation de text-generation-webui, assurez-vous de répondre aux exigences suivantes pour garantir une installation fluide et réussie.
1. Python 3.10 ou supérieur. text-generation-webui est compatible avec Python 3.10 et utilise des fonctionnalités qui peuvent ne pas être disponibles dans les versions antérieures de Python.
2. Git (Optionnel) Utilisation : Téléchargement du code source de text-generation-webui.
git clone https://github.com/oobabooga/text-generation-webui.git
Suivez ces étapes pour télécharger et installer text-generation-webui, y compris la configuration de l’environnement nécessaire pour exécuter le programme sur votre système.
Ouvrez un terminal ou une invite de commandes. Naviguez vers le répertoire où vous souhaitez installer text-generation-webui. Exécutez la commande suivante pour cloner le dépôt :
git clone https://github.com/oobabooga/text-generation-webui.gitAllez sur la page GitHub de text-generation-webui. Cliquez sur le bouton « Download » ou « Télécharger » pour télécharger l’archive du dépôt. Décompressez l’archive dans le répertoire de votre choix.
Ouvrez le dossier de text-generation-webui décompressé et trouvez le fichier start_windows.bat dans le dossier. Ce script est l’installeur automatique prévu pour simplifier l’installation.

Pare-feu : Avant de lancer le script, assurez-vous que votre pare-feu ne bloque pas les téléchargements. L’installeur doit récupérer des librairies d’une taille totale d’environ 5 à 8 Go.
Lancement de l’installation :
Double-cliquez sur start_windows.bat pour démarrer l’installation. Le script commence par installer Microconda en mode portable, directement dans le répertoire d’installation de text-generation-webui, sans nécessiter d’installation système.
Choix du matériel :

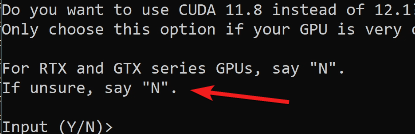
N pour installer la version 12.1 et ne pas opter pour les anciennes versions.Installer_Files. Le poids total de ce dossier peut atteindre au moins 7 Go.Après que l’installation se soit déroulée sans accroc, le serveur se lance de manière automatique, rendant accessible l’interface graphique de text-generation-webui à l’adresse locale 127.0.0.1 sur le port 7860.
http://127.0.0.1:7860/En naviguant vers cette adresse avec un navigateur web, vous serez accueilli par une interface utilisateur comprenant un mode chat et d’autres fonctionnalités prêtes à l’emploi. Cependant, pour que l’expérience soit complète, il vous faut un modèle de langage.
Dans cet exemple, nous optons pour un modèle qui fonctionne exclusivement avec le processeur, possédant l’extension gguf, idéal pour une utilisation simplifiée. Le site Hugging Face héberge une collection spécifique de modèles quantisés et optimisés, parfaitement compatibles avec notre programme. Vous pouvez visiter ce dépôt via le lien suivant : Hugging Face – TheBloke.
Pour débuter, nous sélectionnerons un modèle léger et en Xfrançais, le CapybaraHermes-2.5-Mistral-7B-GGUF, accessible directement à cette adresse : Hugging Face – CapybaraHermes. Ce modèle sera téléchargé via la fonctionnalité intégrée de téléchargement automatique du programme.
Pour ce faire, copiez le nom du modèle depuis le site de Hugging Face.

Rendez-vous ensuite dans l’interface de text-generation-webui, plus précisément dans l’onglet modèle. À droite, vous verrez un champ où vous pourrez coller le nom du dépôt que vous avez copié.

Mais avant de finaliser, il est essentiel de sélectionner la version spécifique du modèle désiré, en l’occurrence une version quantisée à 4 bits (Q4_0). Pour cela, retournez sur le dépôt Hugging Face, cliquez sur l’onglet « Files and Versions », sélectionnez le modèle approprié, et copiez le nom du fichier.

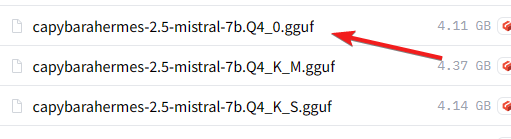
De retour dans l’interface de text-generation-webui, collez le nom du fichier dans le champ prévu à cet effet, marqué « File Name for GGUF Model », puis lancez le téléchargement.
Ce processus mettra à disposition le modèle au sein de votre installation de text-generation-webui, vous permettant d’exploiter pleinement les capacités de génération de texte de manière locale et optimisée. Pour information, les modèles sont simplement téléchargés dans le dossier models.
Une fois le modèle téléchargé, il reste à le charger dans l’interface de text-generation-webui pour commencer à l’utiliser. Voici comment procéder :

lama.cpp. Ce choix est crucial car il assure que le modèle sera chargé et interprété correctement par le programme.load. Cette action initie le chargement du modèle dans l’interface de text-generation-webui. Le processus peut prendre un moment, selon la taille du modèle et les spécifications de votre système.Une fois le modèle chargé, vous pouvez naviguer vers l’onglet chat de l’interface. Vous y trouverez un espace dédié à la conversation, vous permettant d’interagir directement avec votre IA locale. Cet espace de chat fonctionne de manière similaire à d’autres interfaces de modèles de langage, mais avec l’avantage d’être exécuté localement sur votre machine. Et voilà, vous êtes prêt à dialoguer avec votre modèle de langage dans text-generation-webui, explorant ainsi les vastes possibilités de la génération de texte directement sur votre ordinateur.
Apprendre de nouvelles choses avec des guides, explications, discutions sur le développement informatique
